Pixel Motion as Universal Representation for Robot Control
LangToMo: A hierarchical VLA framework for robot control that uses intermediate motion representations.

Abstract
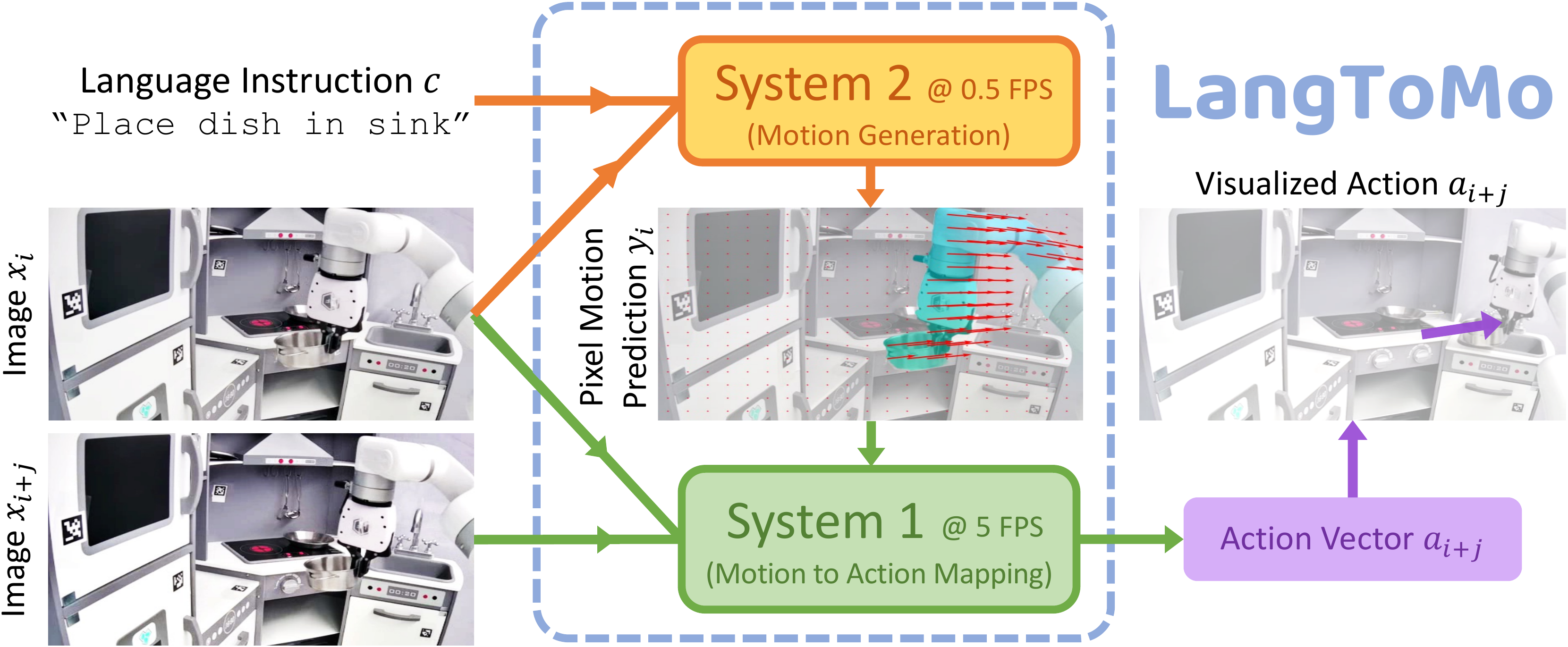
We present LangToMo, a vision-language-action framework structured as a dual-system architecture that uses pixel motion forecasts as intermediate representations. Our high-level System 2, an image diffusion model, generates text-conditioned pixel motion sequences from a single frame to guide robot control. Pixel motion—a universal, interpretable, and motion-centric representation—can be extracted from videos in a self-supervised manner, enabling diffusion model training on web-scale video-caption data. Treating generated pixel motion as learned universal representations, our low level System 1 module translates these into robot actions via motion-to-action mapping functions, which can be either hand-crafted or learned with minimal supervision. System 2 operates as a high-level policy applied at sparse temporal intervals, while System 1 acts as a low-level policy at dense temporal intervals. This hierarchical decoupling enables flexible, scalable, and generalizable robot control under both unsupervised and supervised settings, bridging the gap between language, motion, and action.
LangToMo Architecture

We learn to forecast pixel motion as universal motion features from video-caption pairs using scalable, self-supervised training of a diffusion model. This diffusion model is used as our System 2 which predicts the next action as pixel motions given the initial observation and goal condition. This System 2 forecasts motion at sparse intervals, while System 1 maps it to dense action vectors.