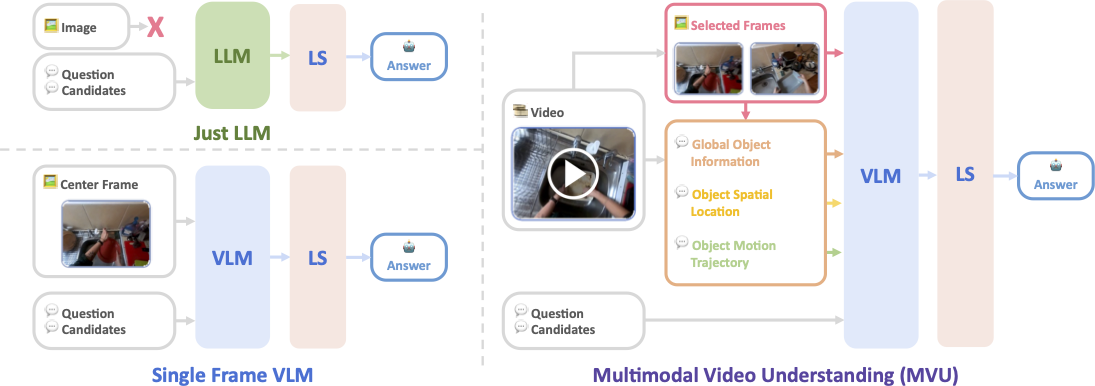
Only an LLM is enough?

- Performs on par with SOTA on Long-Video Understanding Benchmarks
- Accuracy of 52.8% on EgoSchema-S and 40.1% on Next-QA using only question as input
- Uses zero task specific information!
- Answers correctly using strong world knowledge of LLM?
- Do existing LLM based methods actually use video then?